基础架构图
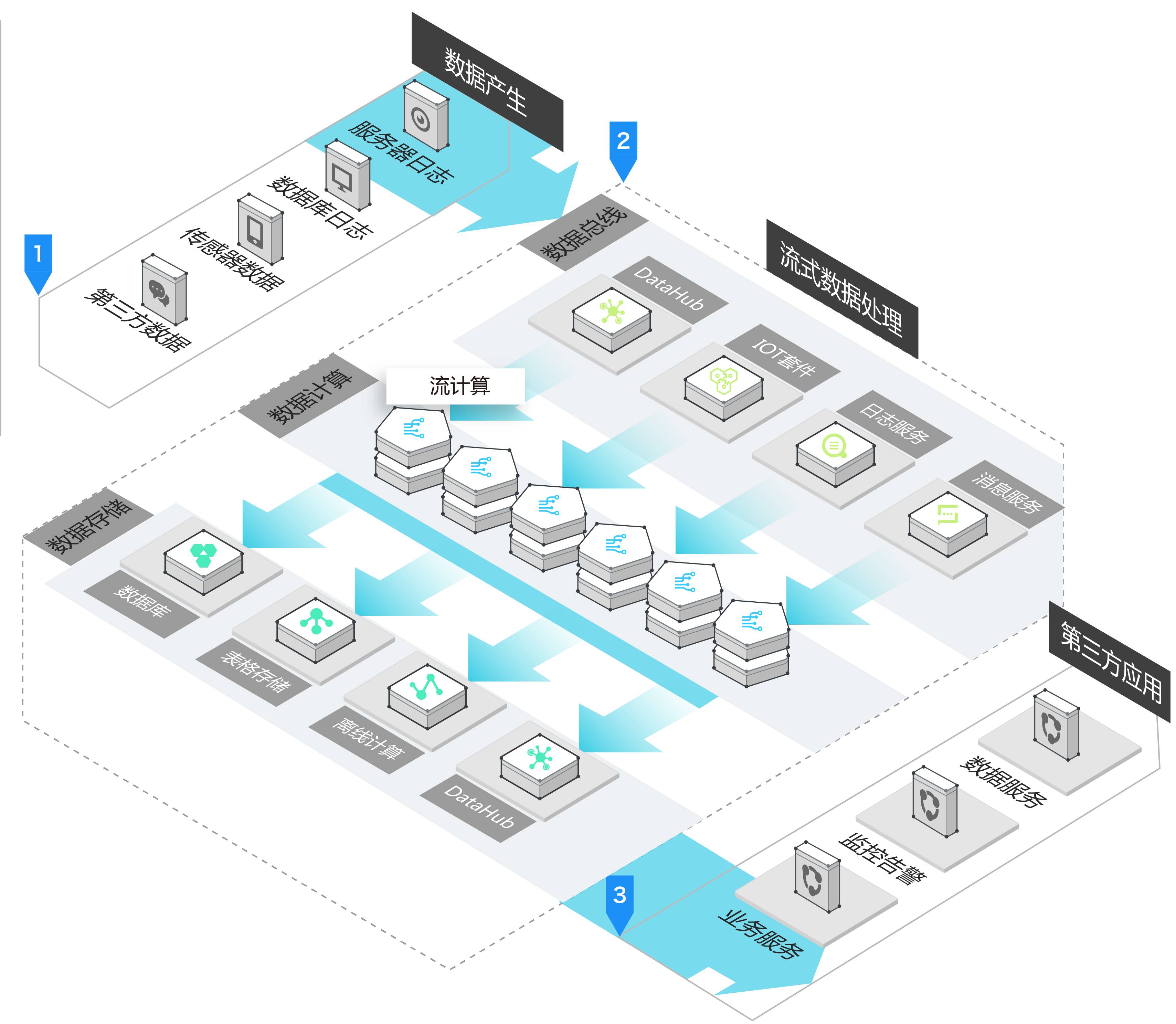
流技术模块划分
数据产生
业务数据生成器
流式存储
不同于传统数据存储,流式数据存储提供了流式数据的发布和订阅功能,让数据的生产者和消费者以消息方式使用流式数据。
流式计算
基于业务的BI, DATAWARE HOUSE,DEVELOPMENT
数据存储
数据存储提供流计算的计算结果存储功能,流计算将最终计算结果写入数据存储,为下游消费做好存储准备。
第三方应用 基于接口的数据消费
- 生产数据
- 日志分析
- 数据展现
存储选型
Casssandra
内部机制
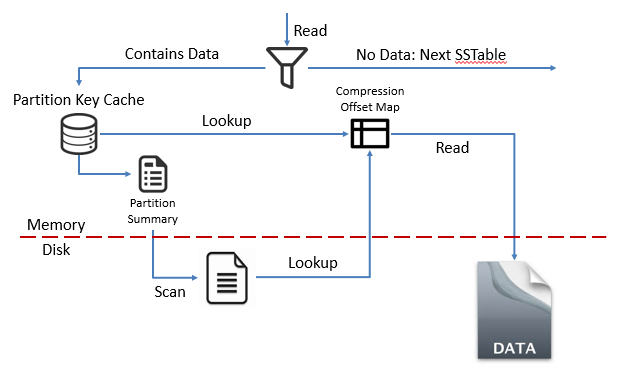
Cassandra 内部使用Log-Structured 和 Merge-Tree 类似数据结构:
- 内存中的
Memtable记录最近的修改 - 磁盘中的
Commit log - 磁盘中持久化的
SSTable。每个SSTable都有Bloom Filter,以用来判断与其关联的SSTable是否包含当前查询所请求的一条或多条数据。如果是,Cassandra将尝试从该SSTable中取出数据;如果不是则会忽略该SSTable,以减少不必要的磁盘访问。
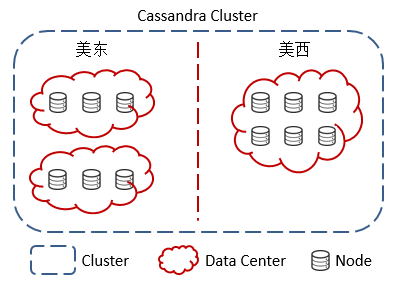
集群
在一个Cassandra集群中常常包含着以下一系列组成:结点Node,数据中心Data Center以及集群Cluster。结点是Cassandra集群中用来存储数据的最基础结构;数据中心则是处于同一地理区域的一系列结点的集合;而集群则常常由多个处于不同区域的数据中心所组成:
存储机制
Cassandra的写入流程也与Log-Structured Merge-Tree的写入流程非常类似:Log-Structured Merge-Tree中的日志对应着Commit Log,C0树对应着Memtable,而C1树则对应着SSTable的集合。在写入时,Cassandra会首先将数据写入到Memtable中,同时在Commit Log的末尾添加该写入所对应的记录。这样在机器断电等异常情况下,Cassandra仍能通过Commit Log来恢复Memtable中的数据。
在持续地写入数据后,Memtable的大小将逐渐增长。在其大小到达某个阈值时,Cassandra的数据迁移流程就将被触发。该流程一方面会将Memtable中的数据添加到相应的SSTable的末尾,另一方面则会将Commit Log中的写入记录移除。
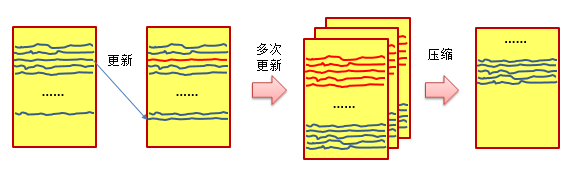
这也就会造成一个容易让读者困惑的问题:如果是将新的数据写入到SSTable的末尾,那么数据迁移的过程该如何执行对数据的更新?答案就是:在需要对数据进行更新时,Cassandra会在SSTable的末尾添加一条具有当前时间戳的记录,以使得其能够标明自身为最新的记录。而原有的在SSTable中的记录随即宣告失效。
这会导致一个问题,那就是对数据的大量更新会导致SSTable所占用的磁盘空间迅速增长,而且其中所记录的数据很多都已经是过期数据。因此在一段时间之后,磁盘的空间利用率会大幅下降。此时我们就需要通过压缩SSTable的方式释放这些过期数据所占用的空间:
优点
- 模式灵活 :使用Cassandra,像文档存储,你不必提前解决记录中的字段。你可以在系统运行时随意的添加或移除字段。这是一个惊人的效率提升,特别是在大型部 署上。
- 真正的可扩展性 :Cassandra是纯粹意义上的水平扩展。为给集群添加更多容量,可以指向另一台电脑。你不必重启任何进程,改变应用查询,或手动迁移任何数据。
- 多数据中心识别 :你可以调整你的节点布局来避免某一个数据中心起火,一个备用的数据中心将至少有每条记录的完全复制。
- 范围查询 :如果你不喜欢全部的键值查询,则可以设置键的范围来查询。
- 列表数据结构 :在混合模式可以将超级列添加到5维。对于每个用户的索引,这是非常方便的。
- 分布式写操作 :有可以在任何地方任何时间集中读或写任何数据。并且不会有任何单点失败。
缺点
- 它未采用hdfs文件系统,所以存在与Hadoop难以协同的问题。数据源在cassandra存储体系中,不利于mapreduce分析。